让 Tokio 调度器速度提升 10 倍
2019 年 10 月 13 日
我们一直在努力开发 Tokio 的下一个主要版本,Rust 的异步运行时。今天,调度器的完全重写已作为 pull request 提交。结果是巨大的性能和延迟改进。一些基准测试显示速度提升了 10 倍!这些改进对“全栈”用例的影响程度始终不明确,因此我们还测试了这些调度器改进对 Hyper 和 Tonic 等用例的影响(剧透:效果非常好)。
在准备开发新的调度器时,我花时间搜索了关于调度器实现的资源。除了现有的实现之外,我没有找到太多。我还发现现有实现的源代码难以理解。为了弥补这一点,我试图尽可能保持 Tokio 新调度器实现的简洁。我还撰写这篇关于实现调度器的详细文章,希望能对处境相似的其他人有所帮助。
本文首先概述了调度器设计的高级概念,包括工作窃取调度器。然后深入探讨了新 Tokio 调度器中进行的具体优化。
涵盖的优化包括
主要主题是“减少”。毕竟,没有代码比没有代码更快!
本文还介绍了测试新调度器。编写正确、并发、无锁的代码真的很难。缓慢但正确总比快速但有缺陷要好,特别是如果这些缺陷与内存安全有关。然而,最好的选择是快速且正确,因此我们编写了 loom,一个用于测试并发的工具。
在深入探讨之前,我想表达一些感谢。
- @withoutboats 和其他致力于 Rust 的
async / await功能的人。你们做得非常出色。这是一个杀手级功能。 - @cramertj 和其他设计
std::task的人。与我们以前拥有的相比,这是一个巨大的改进。同样,你们也做得非常出色。 - Buoyant,Linkerd 的制造商,更重要的是我的雇主。感谢你们让我花这么多时间在这项工作上。需要服务网格的读者,请查看 Linkerd。它很快将包含本文中讨论的所有优点。
- Go,感谢你们拥有如此出色的调度器实现。
拿起一杯咖啡,让自己舒适一下。这将是一篇很长的文章。
调度器,它们是如何工作的?
调度器的作用是调度工作。一个应用程序被分解成工作单元,我们称之为任务。当任务可以取得进展时,它是可运行的,当它被外部资源阻塞时,它不再可运行(或空闲)。任务是独立的,因此任意数量的可运行任务可以并发执行。调度器负责执行处于运行状态的任务,直到它们转换回空闲状态。执行任务意味着将 CPU 时间(一种全局资源)分配给任务。
本文讨论用户空间调度器,即在操作系统线程之上运行的调度器(操作系统线程又由内核级调度器驱动)。Tokio 调度器执行 Rust futures,可以将其视为“异步绿色线程”。这是 M:N 线程模式,其中许多用户级任务被多路复用到少量操作系统线程上。
有许多不同的调度器建模方式,每种方式都有优点和缺点。在最基本的层面上,调度器可以建模为一个运行队列和一个处理器,处理器消耗队列中的任务。处理器是一段在线程上运行的代码。用伪代码表示,它执行以下操作
while let Some(task) = self.queue.pop() {
task.run();
}
当一个任务变为可运行时,它会被插入到运行队列中。
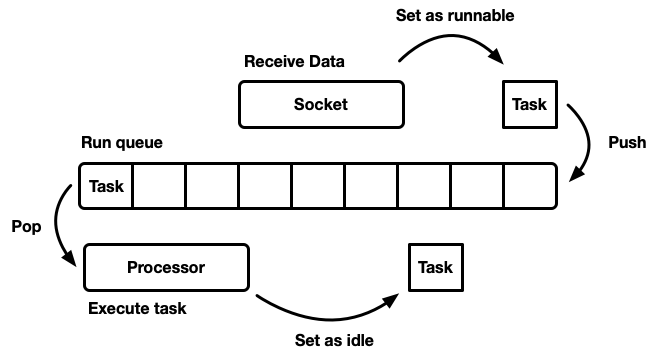
虽然可以设计一个系统,使资源、任务和处理器都存在于单个线程上,但 Tokio 选择使用多线程。我们生活在一个计算机配备多个 CPU 的世界。设计单线程调度器会导致硬件利用率不足。我们希望利用我们所有的 CPU。有几种方法可以做到这一点
- 一个全局运行队列,多个处理器。
- 多个处理器,每个处理器都有自己的运行队列。
一个队列,多个处理器
在这种模型中,存在一个单一的全局运行队列。当任务变为可运行时,它们会被推送到队列的尾部。有多个处理器,每个处理器都在单独的线程上运行。每个处理器从队列的头部弹出任务,如果没有任务可用则阻塞线程。
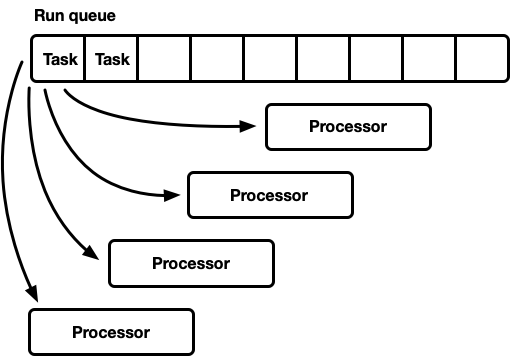
运行队列必须支持多个生产者和多个消费者。常用的算法是侵入式链表。侵入式意味着任务结构包含指向运行队列中下一个任务的指针,而不是用链表节点包装任务。这样,可以避免推送和弹出操作的内存分配。可以使用无锁推送操作,但弹出需要[^1]互斥锁来协调消费者。
[^1]:从技术上讲,可以实现无锁多消费者队列。然而,实际上,正确避免锁所需的开销大于仅使用互斥锁。
这种方法通常在实现通用线程池时使用,因为它有几个优点
- 任务被公平地调度。
- 实现相对简单。可以将现成的队列与上面草绘的处理器循环配对。
关于公平性的简要说明。调度公平性意味着任务按照先进先出的顺序调度。首先转换为运行状态的任务首先执行。通用调度器试图做到公平,但有些用例,例如使用 fork-join 并行化计算,唯一重要的因素是最终结果计算的速度,而不是每个子任务的公平性。
这种调度器模型有一个缺点。所有处理器都争夺队列的头部。对于通用线程池,这通常不是一个主要的障碍。处理器执行任务所花费的时间远远超过从运行队列中弹出任务所花费的时间。当任务执行时间较长时,队列争用会减少。然而,Rust 的异步任务在从运行队列中弹出时预计执行时间非常短。在这种情况下,队列争用的开销变得显着。
并发和机械同情。
为了从程序中获得最佳运行时性能,我们必须将其设计为利用硬件的运行方式。“机械同情”一词由 Martin Thompson 应用于软件(他的博客虽然不再更新,但仍然包含许多相关知识)。
详细讨论现代硬件如何处理并发超出了本文的范围。从 10,000 英尺的高度来看,硬件性能的提升不是通过速度更快,而是通过为应用程序提供更多的 CPU 核心(我的笔记本电脑有 6 个!)。每个核心都可以在极短的时间内执行大量的计算。相对而言,缓存和内存访问等操作需要更长的时间。因此,为了使应用程序快速运行,我们必须最大化每次内存访问的 CPU 指令数量。虽然编译器可以为我们做很多工作,但作为开发人员,我们确实需要考虑诸如结构布局和内存访问模式之类的事情。
当涉及到并发线程时,行为与单线程非常相似,直到并发修改发生在同一个缓存行或请求顺序一致性。然后,CPU 的缓存一致性协议将不得不开始工作,以确保每个 CPU 的缓存保持最新。
这一切都是为了说明一个显而易见的事实:尽可能避免跨线程同步,因为它很慢。
多个处理器,每个处理器都有自己的运行队列
另一种调度器建模方式是使用多个单线程调度器。每个处理器都有自己的运行队列,任务被绑定到特定的处理器。这完全避免了同步问题。由于 Rust 的任务模型要求能够从任何线程排队任务,因此仍然需要一种线程安全的方式将任务注入到调度器中。要么每个处理器的运行队列都支持线程安全的推送操作 (MPSC),要么每个处理器都有两个运行队列:一个非同步队列和一个线程安全队列。
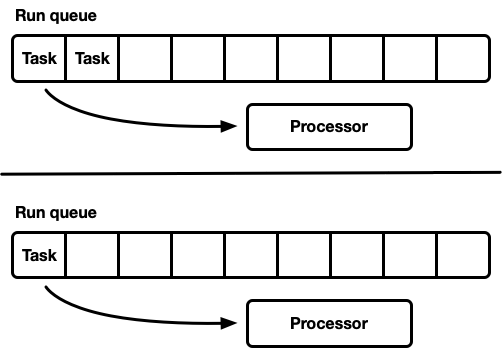
这是 Seastar 使用的策略。由于几乎完全避免了同步,因此这种策略可能非常快。然而,它不是万能的。除非工作负载完全均匀,否则某些处理器会变得空闲,而其他处理器则处于负载之下,从而导致资源利用率不足。发生这种情况是因为任务被绑定到特定的处理器。当一批任务在单个处理器上调度时,即使其他处理器处于空闲状态,该单个处理器也负责处理峰值。
大多数“真实世界”的工作负载都不是均匀的。因此,通用调度器倾向于避免这种模型。
工作窃取调度器
工作窃取调度器建立在分片调度器模型之上,并解决了利用率不足的问题。每个处理器维护自己的运行队列。变为可运行的任务被推送到当前处理器的运行队列中,处理器消耗其本地运行队列中的任务。但是,当处理器变为空闲时,它会检查兄弟处理器的运行队列,并尝试从中窃取任务。只有当处理器无法从兄弟运行队列中找到工作时,它才会进入休眠状态。
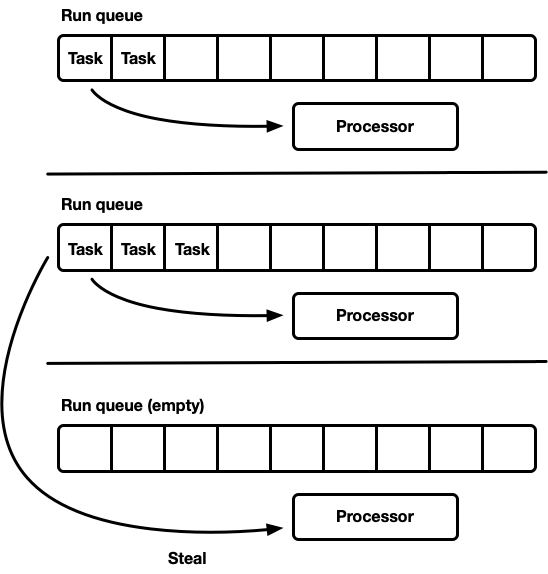
在模型层面,这是一种“两全其美”的方法。在负载下,处理器独立运行,避免了同步开销。在负载在处理器之间分布不均匀的情况下,调度器能够重新分配。由于这种特性,工作窃取调度器是 Go、Erlang、Java 和其他语言的选择。
缺点是这种方法要复杂得多;运行队列算法必须支持窃取操作,并且需要一些跨处理器同步才能保持平稳运行。如果做得不正确,实现工作窃取模型的开销可能会大于所获得的收益。
考虑这种情况:处理器 A 当前正在运行一个任务,并且有一个空的运行队列。处理器 B 处于空闲状态;它尝试窃取任务但失败,因此它进入休眠状态。然后,处理器 A 正在执行的任务派生出 20 个任务。目标是让处理器 B 唤醒并窃取其中一些新派生的任务。为了实现这一点,工作窃取调度器需要一些启发式方法,当处理器观察到其队列中有新工作时,会向休眠的兄弟处理器发出信号。当然,这会引入额外的同步,因此必须最大限度地减少此操作。
总结
- 最小化同步是好的。
- 工作窃取是通用调度器的首选算法。
- 每个处理器在很大程度上是独立的,但窃取需要一些同步。
Tokio 0.1 调度器
Tokio 在 2018 年 3 月 首次发布了其工作窃取调度器。这是基于一些被证明是不正确的假设的第一次尝试。
首先,Tokio 0.1 调度器假设如果处理器线程空闲一段时间,则应将其关闭。调度器最初旨在成为 Rust futures 的“通用”线程池执行器。当调度器首次编写时,Tokio 仍处于“tokio-core”时代。在这一点上,模型是在与 I/O 选择器(epoll、kqueue、iocp 等)位于同一位置的单个线程上执行基于 I/O 的任务。更多 CPU 绑定的工作可以转移到线程池。在这种情况下,活动线程的数量应该是灵活的,关闭空闲线程更有意义。但是,模型已转变为在工作窃取调度器上运行所有异步任务,在这种情况下,保持少量线程始终处于活动状态更有意义。
其次,它使用了 crossbeam deque 实现。此实现基于 Chase-Lev deque,由于下面描述的原因,它不适合调度独立异步任务的用例。
第三,实现过于复杂。部分原因是这是我第一次实现调度器。此外,我过于热衷于在互斥锁可以很好地完成工作的代码路径中使用原子操作。一个重要的教训是,在许多情况下,互斥锁是最佳选择。
最后,最初的实现包含许多小的低效之处。Rust 的异步模型的细节在早期发生了显着变化,但库在这些年中保持了 API 稳定性。这导致积累了一些债务,现在可以偿还了。
随着 tokio 接近其首次重大破坏性发布,我们可以用这些年来的经验教训偿还所有债务。这是一个激动人心的时刻!
下一代 Tokio 调度器
现在是深入研究新调度器中发生的变化的时候了。
新的任务系统
首先,重要的是要强调一些不是 Tokio 的一部分,但对于实现某些收益至关重要的东西:std 中包含的新任务系统,主要由 Taylor Cramer 设计。该系统提供了调度器必须实现的钩子,以执行 Rust 异步任务,并且它做得非常好。它比以前的迭代版本更轻巧、更灵活。
Waker 结构由资源持有,用于发出任务可运行的信号,并推送到调度器的运行队列中。在新任务系统中,Waker 结构是两个指针宽,而以前要大得多。缩小尺寸对于最大限度地减少复制 Waker 值的开销非常重要,同时也可以减少结构中的空间占用,从而允许更多关键数据适应缓存行。自定义的 vtable 设计实现了许多优化,稍后将进行讨论。
更好的运行队列
运行队列是调度器的核心。因此,它可能是最关键的组件,需要正确实现。最初的 Tokio 调度器使用了 crossbeam 的 deque 实现,它是单生产者、多消费者 deque。任务被推送到一端,值从另一端弹出。大多数时候,推送值的线程将弹出它,但是,其他线程偶尔会通过自己弹出值来“窃取”。deque 由一个数组和一组跟踪头部和尾部索引的索引支持。当 deque 满时,推送到它会导致存储增长。分配一个新的、更大的数组,并将值移动到新的存储中。
deque 增长的能力带来了复杂性和开销成本。推送/弹出操作必须考虑这种增长。此外,在增长时,释放原始数组会带来额外的困难。在垃圾回收语言中,旧数组将超出范围,最终 GC 会释放它。但是,Rust 不附带 GC。这意味着我们负责释放数组,但线程可能正在并发访问内存。Crossbeam 对此的回答是使用 基于 epoch 的回收策略。虽然不是非常昂贵,但它确实在热路径中增加了非平凡的开销。现在,每个操作都必须在进入和退出临界区时发出原子 RMW(读取-修改-写入)操作,以向其他线程发出信号,表明内存正在使用中并避免释放。
由于与增长运行队列相关的成本,值得调查增长队列是否是必需的。这个问题最终促使了调度器的重写。新调度器的策略是使用固定大小的每进程队列。当队列已满时,不是增长本地队列,而是将任务推送到全局的、多消费者、多生产者的队列中。处理器需要偶尔检查这个全局队列,但频率远低于本地队列。
一个早期的实验用有界的 mpmc 队列替换了 crossbeam 队列。由于推送和弹出执行的同步量,这并没有带来太多改进。关于工作窃取用例,要记住的关键一点是,在负载下,队列上几乎没有争用,因为每个处理器只访问自己的队列。
此时,我选择更仔细地阅读 Go 源代码,并发现他们使用了固定大小的单生产者、多消费者队列。这个队列令人印象深刻的地方在于它运行所需的同步非常少。我最终调整了该算法以在 Tokio 调度器中使用,并做了一些更改。值得注意的是,Go 实现对其原子操作使用顺序一致性(基于我对 Go 的有限了解)。作为 Tokio 调度器一部分实现的版本还减少了一些不频繁代码路径中的复制。
队列实现是一个循环缓冲区,使用数组来存储值。原子整数用于跟踪头部和尾部位置。
struct Queue {
/// Concurrently updated by many threads.
head: AtomicU32,
/// Only updated by producer thread but read by many threads.
tail: AtomicU32,
/// Masks the head / tail position value to obtain the index in the buffer.
mask: usize,
/// Stores the tasks.
buffer: Box<[MaybeUninit<Task>]>,
}
推送到队列由单个线程完成
loop {
let head = self.head.load(Acquire);
// safety: this is the **only** thread that updates this cell.
let tail = self.tail.unsync_load();
if tail.wrapping_sub(head) < self.buffer.len() as u32 {
// Map the position to a slot index.
let idx = tail as usize & self.mask;
// Don't drop the previous value in `buffer[idx]` because
// it is uninitialized memory.
self.buffer[idx].as_mut_ptr().write(task);
// Make the task available
self.tail.store(tail.wrapping_add(1), Release);
return;
}
// The local buffer is full. Push a batch of work to the global
// queue.
match self.push_overflow(task, head, tail, global) {
Ok(_) => return,
// Lost the race, try again
Err(v) => task = v,
}
}
请注意,在此 push 函数中,唯一的原子操作是具有 Acquire 排序的加载和具有 Release 排序的存储。没有读取-修改-写入操作(compare_and_swap、fetch_and、...)或顺序一致性。这很重要,因为在 x86 芯片上,所有加载/存储都已经是“原子”的。因此,在 CPU 级别,此函数没有同步。使用原子操作会影响编译器,因为它会阻止某些优化,但仅此而已。第一个 load 最有可能可以使用 Relaxed 排序安全地完成,但切换后没有可衡量的增益。
当队列已满时,将调用 push_overflow。此函数将本地队列中一半的任务移动到全局队列中。全局队列是由互斥锁保护的侵入式链表。移动到全局队列的任务首先链接在一起,然后获取互斥锁并通过更新全局队列的尾部指针插入所有任务。这保持了临界区的小尺寸。
如果您熟悉原子内存排序的详细信息,您可能会注意到上面显示的 push 函数存在潜在的“问题”。具有 Acquire 排序的原子 load 非常弱。它可能会返回陈旧的值,即并发窃取操作可能已经增加了 self.head 的值,但执行 push 的线程在缓存中有一个旧值,因此它没有注意到窃取操作。这对算法的正确性没有问题。在 push 的快速路径中,我们只关心本地运行队列是否已满。鉴于当前线程是唯一可以推送到运行队列中的线程,陈旧的 load 将导致将运行队列视为比实际更满。它可能会错误地确定队列已满并进入 push_overflow 函数,但此函数包含更强的原子操作。如果 push_overflow 确定队列实际上未满,它将返回 Err,并且 push 操作会再次尝试。这是 push_overflow 将一半的运行队列移动到全局队列的另一个原因。通过移动一半的队列,“运行队列为空”的误报命中率会大大降低。
本地 pop(来自拥有队列的处理器)也很轻量
loop {
let head = self.head.load(Acquire);
// safety: this is the **only** thread that updates this cell.
let tail = self.tail.unsync_load();
if head == tail {
// queue is empty
return None;
}
// Map the head position to a slot index.
let idx = head as usize & self.mask;
let task = self.buffer[idx].as_ptr().read();
// Attempt to claim the task read above.
let actual = self
.head
.compare_and_swap(head, head.wrapping_add(1), Release);
if actual == head {
return Some(task.assume_init());
}
}
在此函数中,有一个原子加载和一个具有 release 的 compare_and_swap。主要开销来自 compare_and_swap。
steal 函数类似于 pop 函数,但来自 self.tail 的加载必须是原子的。此外,类似于 push_overflow,窃取操作将尝试声明一半的队列而不是单个任务。这有一些不错的特性,我们稍后将介绍。
最后一个缺失的部分是消耗全局队列。此队列用于处理来自处理器本地队列的溢出以及从非处理器线程向调度器提交任务。如果处理器处于负载状态,即本地运行队列有任务。处理器将在从本地队列执行约 60 个任务后尝试从全局队列弹出。它还在“搜索”状态(如下所述)时检查全局队列。
针对消息传递模式进行优化
使用 Tokio 编写的应用程序通常以许多小的、独立的任务建模。这些任务将使用消息传递相互通信。这种模式与其他语言(如 Go 和 Erlang)类似。鉴于这种模式的常见程度,调度器尝试对其进行优化是有意义的。
给定任务 A 和任务 B。任务 A 当前正在执行,并通过通道向任务 B 发送消息。该通道是任务 B 当前被阻塞的资源,因此发送消息的操作将导致任务 B 转换为可运行状态并推送到当前处理器的运行队列中。然后,处理器将从运行队列中弹出下一个任务,执行它,并重复此操作,直到到达任务 B。
问题是在发送消息和任务 B 被执行之间可能存在显着的延迟。此外,当发送“热”数据(例如消息)时,它会存储在 CPU 的缓存中,但当任务 B 被调度时,相关缓存很可能已被清除。
为了解决这个问题,新的 Tokio 调度器实现了一个优化(在 Go 和 Kotlin 的调度器中也发现了)。当任务转换为可运行状态时,不是将其推送到运行队列的末尾,而是将其存储在特殊的“下一个任务”槽中。处理器始终会在检查运行队列之前检查此槽。当将任务插入到此槽中时,如果该槽中已存储了任务,则旧任务将从该槽中删除并推送到运行队列的末尾。在消息传递的情况下,这将导致消息的接收者被调度为下一个运行。

限制窃取
在工作窃取调度器中,当处理器的运行队列为空时,处理器将尝试从兄弟处理器窃取任务。为此,选择一个随机的兄弟处理器作为起点,处理器对该兄弟处理器执行窃取操作。如果未找到任务,则尝试下一个兄弟处理器,依此类推,直到找到任务。
在实践中,许多处理器通常会在大约同一时间完成处理其运行队列。当一批工作到达时(例如,当轮询 epoll 以获取套接字就绪状态时),就会发生这种情况。处理器被唤醒,它们获取任务,运行它们,然后完成。这导致所有处理器同时尝试窃取,这意味着许多线程尝试访问相同的队列。这会产生争用。随机选择起点有助于减少争用,但它仍然可能非常糟糕。
为了解决这个问题,新的调度器限制了执行窃取操作的并发处理器数量。我们将处理器尝试窃取的处理器状态称为“搜索工作”状态,或简称“搜索”状态(稍后会提到)。此优化是通过使用一个原子整数来实现的,处理器在开始搜索之前递增该整数,并在退出搜索状态时递减该整数。搜索者的最大数量是处理器总数的一半。也就是说,该限制是粗略的,但这没关系。我们不需要对搜索者的数量进行硬性限制,只需要一个节流阀。我们用精度换取算法效率。
一旦处于搜索状态,处理器就会尝试从兄弟工作线程窃取任务并检查全局队列。
减少跨线程同步
工作窃取调度器的另一个关键部分是兄弟通知。这是处理器在观察到新任务时通知兄弟处理器的地方。如果兄弟处理器处于休眠状态,它会唤醒并窃取任务。通知操作还有另一个关键责任。回想一下,队列算法使用了弱原子排序(Acquire / Release)。由于原子内存排序的工作方式,如果没有额外的同步,则无法保证兄弟处理器会看到队列中的任务进行窃取。通知操作还负责建立必要的同步,以便兄弟处理器看到任务以便窃取它们。这些要求使通知操作变得昂贵。目标是在不导致 CPU 利用率不足的情况下尽可能少地执行通知操作,即处理器有任务,而兄弟处理器无法窃取它们。过度热情的通知会导致惊群效应问题。
最初的 Tokio 调度器对通知采取了一种幼稚的方法。每当新任务被推送到运行队列时,就会通知一个处理器。每当一个处理器被通知并在唤醒时找到一个任务时,它都会通知另一个处理器。这种逻辑很快导致所有处理器都被唤醒并搜索工作(导致争用)。通常,这些处理器中的大多数都未能找到工作并返回休眠状态。
新的调度器通过借用 Go 调度器中使用的相同技术,在此方面取得了重大改进。通知尝试与之前的调度器在相同的点进行,但是,只有在没有处于搜索状态的工作线程时,才会发生通知(请参阅上一节)。当工作线程被通知时,它会立即转换为搜索状态。当处于搜索状态的处理器找到新任务时,它将首先退出搜索状态,然后通知另一个处理器。
此逻辑具有限制处理器唤醒速率的效果。如果一次调度一批任务(例如,当轮询 epoll 以获取套接字就绪状态时),第一个任务将导致通知一个处理器。该处理器现在处于搜索状态。批处理中剩余的已调度任务将不会通知处理器,因为至少有一个处理器处于搜索状态。被通知的处理器将窃取批处理中一半的任务,然后又通知另一个处理器。第三个处理器将唤醒,从前两个处理器之一中找到任务并窃取其中的一半。这导致处理器的平稳增加以及任务的快速负载均衡。
减少内存分配
新的 Tokio 调度器每个生成的任务只需要一次分配,而旧的调度器需要两次。 之前,Task 结构体看起来像这样
struct Task {
/// All state needed to manage the task
state: TaskState,
/// The logic to run is represented as a future trait object.
future: Box<dyn Future<Output = ()>>,
}
然后,Task 结构体也会在 Box 中分配。 这一直是我长期以来想要解决的一个缺陷(我 在 2014 年首次尝试 修复这个问题)。 自旧的 Tokio 调度器以来,发生了两件事。 首先,std::alloc 稳定了。 其次,Future 任务系统切换到了显式的 vtable 策略。 这些是最终消除每个任务双重分配低效率所需的两个缺失部分。
现在,Task 结构表示为
struct Task<T> {
header: Header,
future: T,
trailer: Trailer,
}
Header 和 Trailer 都是驱动任务所需的状态,但它们被分为“热”数据(header)和“冷”数据(trailer),即大致上是经常访问的数据和很少使用的数据。 热数据放置在结构体的头部,并尽可能保持小尺寸。 当 CPU 解引用任务指针时,它将一次加载一个缓存行大小的数据量(介于 64 到 128 字节 之间)。 我们希望这些数据尽可能相关。
减少原子引用计数
本文中我们将讨论的最后一个优化是新调度器如何减少所需的原子引用计数数量。 任务结构有很多未完成的引用:调度器和每个 waker 都持有一个句柄。 管理此内存的常用方法是使用 原子引用计数。 此策略在每次克隆引用时都需要一个原子操作,并在每次删除引用时都需要一个原子操作。 当最后一个引用超出作用域时,内存将被释放。
在旧的 Tokio 调度器中,每个 waker 都持有一个对任务句柄的计数引用,大致如下
struct Waker {
task: Arc<Task>,
}
impl Waker {
fn wake(&self) {
let task = self.task.clone();
task.scheduler.schedule(task);
}
}
当任务被唤醒时,引用被克隆(原子递增)。 然后,该引用被推入运行队列。 当处理器接收到任务并完成执行后,它会删除引用,从而导致原子递减。 这些原子操作会累加。
std::future 任务系统的设计者之前已经发现了这个问题。 他们观察到,当调用 Waker::wake 时,通常不再需要原始的 waker 引用。 这允许在将任务推入运行队列时重用原子引用计数。 std::future 任务系统现在包含两个 "wake" API
wake,它接受selfwake_by_ref,它接受&self。
这种 API 设计促使调用者使用 wake,这避免了原子递增。 现在实现变为
impl Waker {
fn wake(self) {
task.scheduler.schedule(self.task);
}
fn wake_by_ref(&self) {
let task = self.task.clone();
task.scheduler.schedule(task);
}
}
只有当 可以获取 waker 的所有权以进行唤醒时,这才能避免额外的引用计数开销。 以我的经验来看,几乎总是希望使用 &self 进行唤醒。 使用 self 进行唤醒会阻止重用 waker(在资源发送多个值的情况下很有用,例如通道、套接字...),而且当需要 self 时,实现线程安全的唤醒也更加困难(详细信息将在另一篇文章中介绍)。
新的调度器通过避免 wake_by_ref 中的原子递增,绕过了整个 "wake by self" 问题,使其与 wake(self) 一样高效。 这是通过让调度器维护一个当前所有活动任务(尚未完成)的列表来实现的。 此列表表示将任务推入运行队列所需的引用计数。
此优化的难点在于确保调度器不会从其列表中删除任何任务,直到可以保证该任务不会再次被推入运行队列。 如何管理这些细节超出了本文的范围,但我建议您在源代码中进一步研究。
使用 Loom 实现无畏的(不安全的)并发
编写正确、并发、无锁的代码非常困难。 与快速但有缺陷的代码相比,缓慢但正确的代码更好,尤其是在这些错误与内存安全相关时。 最好的选择是既快速又正确。 新的调度器进行了一些非常激进的优化,并避免了大多数 std 类型,以便编写更专业的版本。 新的调度器中有很多 unsafe 代码。
有几种测试并发代码的方法。 一种是让您的用户为您进行测试和调试(当然,这是一个有吸引力的选择)。 另一种是编写在循环中运行的单元测试,并希望它能捕获错误。 甚至可以加入 TSAN。 当然,如果这确实捕获到一个错误,那么除了再次在循环中运行测试之外,没有其他方法可以轻松重现它。 此外,您要运行循环多长时间? 十秒?十分钟?十天? 这曾经是 Rust 中测试并发代码的状态。
我们认为现状是不可接受的。 当我们发布代码时,我们希望感到自信(好吧,尽可能自信)——尤其是并发的、无锁的代码。 可靠性是 Tokio 用户一直期望的东西。
为了满足我们的需求,我们编写了一个新工具:Loom。 Loom 是一个用于并发代码的排列测试工具。 测试像往常一样编写,但是当它们使用 loom 执行时,loom 将多次运行测试,排列测试能够在线程环境中遇到的所有可能的执行和行为。 它还验证正确的内存访问、释放内存等...
作为一个例子,这是一个针对新调度器的 loom 测试
#[test]
fn multi_spawn() {
loom::model(|| {
let pool = ThreadPool::new();
let c1 = Arc::new(AtomicUsize::new(0));
let (tx, rx) = oneshot::channel();
let tx1 = Arc::new(Mutex::new(Some(tx)));
// Spawn a task
let c2 = c1.clone();
let tx2 = tx1.clone();
pool.spawn(async move {
spawn(async move {
if 1 == c1.fetch_add(1, Relaxed) {
tx1.lock().unwrap().take().unwrap().send(());
}
});
});
// Spawn a second task
pool.spawn(async move {
spawn(async move {
if 1 == c2.fetch_add(1, Relaxed) {
tx2.lock().unwrap().take().unwrap().send(());
}
});
});
rx.recv();
});
}
它看起来很正常,但是,loom::model 块中的代码将被运行数千次(可能数百万次),每次行为都会略有不同。 线程的确切顺序每次都会改变。 此外,对于每个原子操作,loom 将尝试 C++11 内存模型允许的所有不同行为。 回想一下,我之前提到过,使用 Acquire 的原子加载相当弱,可能会返回陈旧的值。 loom 测试将尝试可以加载的每个可能的值。
在使用新调度器时,loom 一直是一个非常宝贵的工具。 它捕获了 10 多个其他单元测试、手动测试和压力测试遗漏的错误。
敏锐的读者可能会质疑 loom 测试“所有可能的排列”的说法,这样做是对的。 对行为的朴素排列将导致阶乘级别的组合爆炸。 任何非平凡的测试都永远无法完成。 这个问题已经被研究多年,并且存在许多算法来管理组合爆炸。 Loom 的核心算法基于 动态偏序归约。 该算法能够剪除导致相同执行的排列。 即使这样,状态空间也可能变得太大,以至于无法在合理的时间内(几分钟)完成。 Loom 还允许使用动态偏序归约的有界变体来限制搜索空间。
总而言之,由于使用 Loom 进行了广泛的测试,我对调度器的正确性非常有信心。
结果
那么,既然我们已经讨论完了什么是调度器以及新的 Tokio 调度器如何实现巨大的性能提升... 那么这些提升究竟是什么? 鉴于新的调度器非常新,尚未进行广泛的实际测试。 以下是我们已知的情况。
首先,新的调度器在微基准测试中快得多。 以下是新调度器在某些基准测试中的改进情况。
旧调度器
test chained_spawn ... bench: 2,019,796 ns/iter (+/- 302,168)
test ping_pong ... bench: 1,279,948 ns/iter (+/- 154,365)
test spawn_many ... bench: 10,283,608 ns/iter (+/- 1,284,275)
test yield_many ... bench: 21,450,748 ns/iter (+/- 1,201,337)
新调度器
test chained_spawn ... bench: 168,854 ns/iter (+/- 8,339)
test ping_pong ... bench: 562,659 ns/iter (+/- 34,410)
test spawn_many ... bench: 7,320,737 ns/iter (+/- 264,620)
test yield_many ... bench: 14,638,563 ns/iter (+/- 1,573,678)
基准测试包括
chained_spawn测试递归生成新任务,即生成一个任务,该任务生成一个任务,该任务生成一个任务,....ping_pong分配一个oneshot通道,生成一个任务,该任务在该通道上发送消息。 原始任务等待接收消息。 这是最接近“真实世界”的基准测试。spawn_many测试将任务注入到调度器中,即从调度器上下文外部生成任务。yield_many测试任务自身唤醒。
从旧调度器到新调度器的改进非常令人印象深刻。 然而,这如何在“真实世界”中体现呢? 很难确切地说,但我确实尝试使用新调度器运行 Hyper 基准测试。
这是使用 wrk -t1 -c50 -d10 进行基准测试的 “hello world” Hyper 服务器
旧调度器
Running 10s test @ http://127.0.0.1:3000
1 threads and 50 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 371.53us 99.05us 1.97ms 60.53%
Req/Sec 114.61k 8.45k 133.85k 67.00%
1139307 requests in 10.00s, 95.61MB read
Requests/sec: 113923.19
Transfer/sec: 9.56MB
新调度器
Running 10s test @ http://127.0.0.1:3000
1 threads and 50 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 275.05us 69.81us 1.09ms 73.57%
Req/Sec 153.17k 10.68k 171.51k 71.00%
1522671 requests in 10.00s, 127.79MB read
Requests/sec: 152258.70
Transfer/sec: 12.78MB
仅仅通过切换调度器,每秒请求数就增加了 34%! 当我第一次看到这个时,我非常高兴。 我最初预计增加约 5~10%。 然后我感到难过,因为这也意味着旧的 Tokio 调度器不是那么好,但没关系。 然后我记起 Hyper 已经位居 TechEmpower 基准测试的榜首。 我很兴奋看到新的调度器将如何影响这些排名。
Tonic,一个 gRPC 客户端和服务器,速度提高了约 10%,考虑到 Tonic 尚未高度优化,这已经非常令人印象深刻了。
结论
我真的很高兴最终完成这项工作。 这项工作已经进行了几个月,并将成为 Rust 异步 I/O 发展历程中的一大步。 我对新调度器工作已经展示的改进非常满意。 Tokio 代码库中还有很多可以加速的领域,因此这项新的调度器工作并不是性能方面的终点。
我也希望本文提供的细节量对其他可能尝试编写调度器的人有所帮助。